本帖最后由 topdog 于 2026-3-28 07:45 编辑
介绍一下飞书和看图片识别功能,这是Nanobot原作没有的功能。本来笔者想让Nanobot可以看图纸识别管脚的接法,又想试试多模态大模型的能力就用识别甲骨文和古画的题跋来考试一下它的能力,功能实现之后,被它出色的表现叹服了。它也比手机中大多数的AI App要本领高强了,让普通人具有了古文字专家的能力。可以做到文科和理科双修。 一、飞书通道集成
(1)工作原理
nanobot 使用 WebSocket 长连接 与飞书通信,无需公网 IP 或 Webhook 配置。
飞书服务器 ←WebSocket长连接→ nanobot
(2)配置方法
在 ~/.nanobot/config.json 中配置:
{
"channels": {
"feishu": {
"enabled": true,
"appId": "cli_xxxxxxxxxxxx",
"appSecret": "xxxxxxxxxx",
"encryptKey": "",
"verificationToken": "",
"allowFrom": [],
"reactEmoji": "THUMBSUP"
}
}
}
(3)前置条件
1. 在 https://open.feishu.cn 创建企业自建应用
2. 启用机器人能力
3. 订阅事件:im.message.receive_v1
4. 获取 App ID 和 App Secret
(4)支持的消息类型
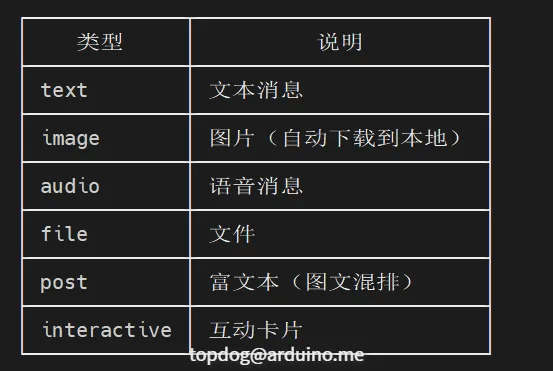
(5)功能特性
- 自动回复表情:收到消息后自动点赞确认
- Markdown 渲染:自动转换为飞书卡片
- 表格支持:Markdown 表格转为交互式表格
- 媒体文件:支持发送图片、文件
二、甲骨文/古画识别

(1)技术架构
功能特性
甲骨文识别:
- 逐字识别甲骨文字形
- 给出每个字的释读结果
- 看不清的字标注 "□"
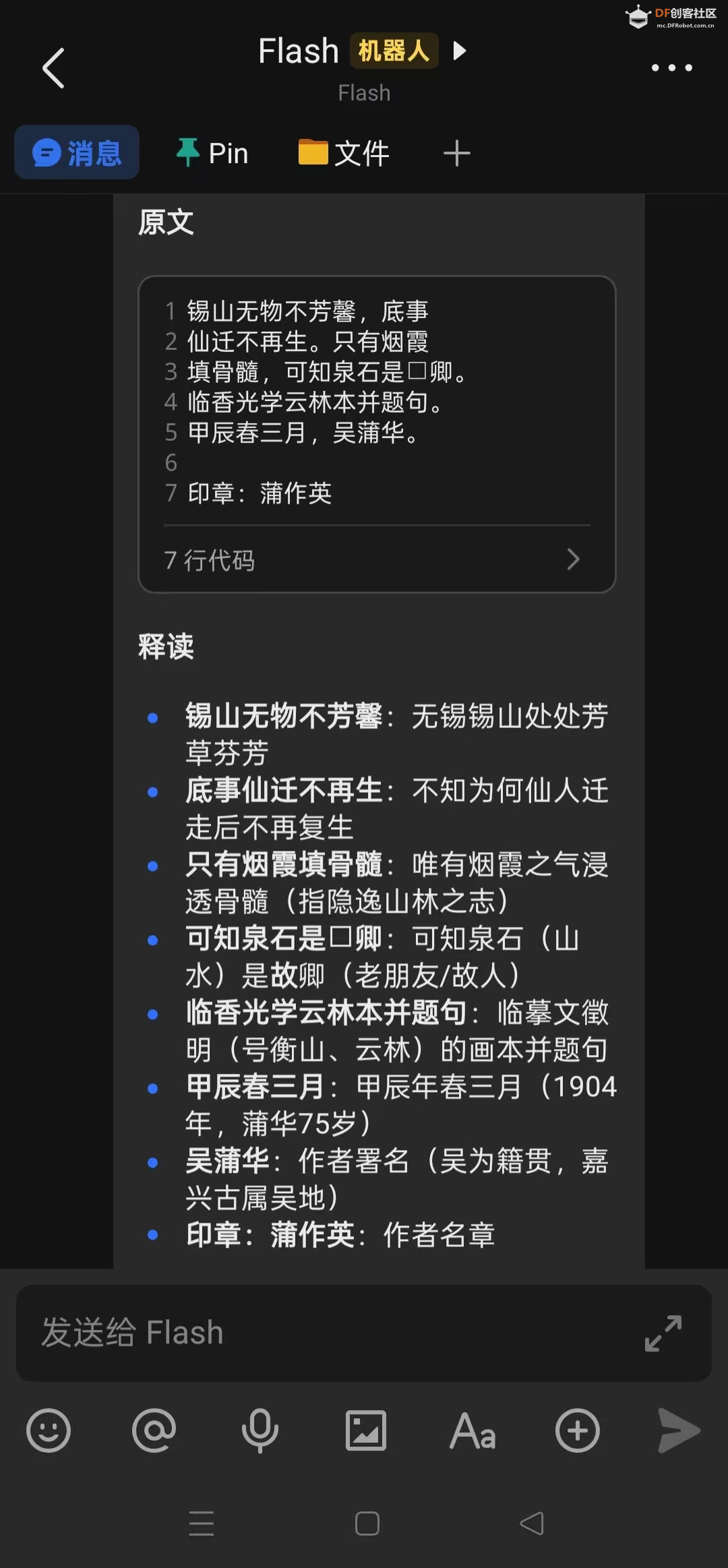
古画/书法识别:
- 识别所有题跋文字
- 识别落款、印章文字
- 提取完整文字内容
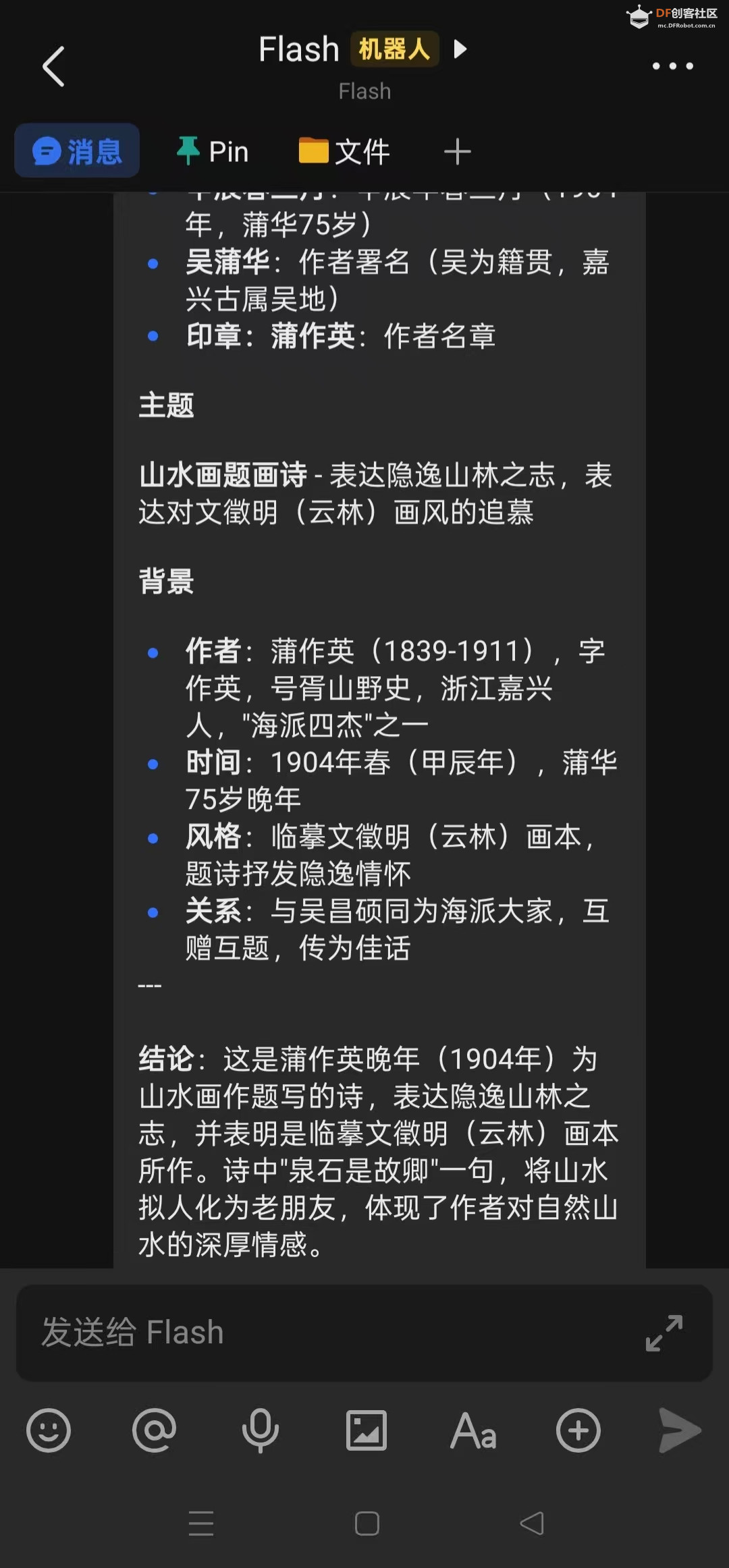
金石铭文:
- 识别碑刻、铜器铭文
- 自动搜索权威资料进行解读
(2)使用方式
用户在飞书中发送图片后,nanobot 会:
1. 自动下载图片到本地 (~/.nanobot/media/)
2. 调用 recognize_image 工具识别
3. 使用网络搜索查询相关权威资料
4. 返回专业解读,然后把下载的图片删除
示例对话
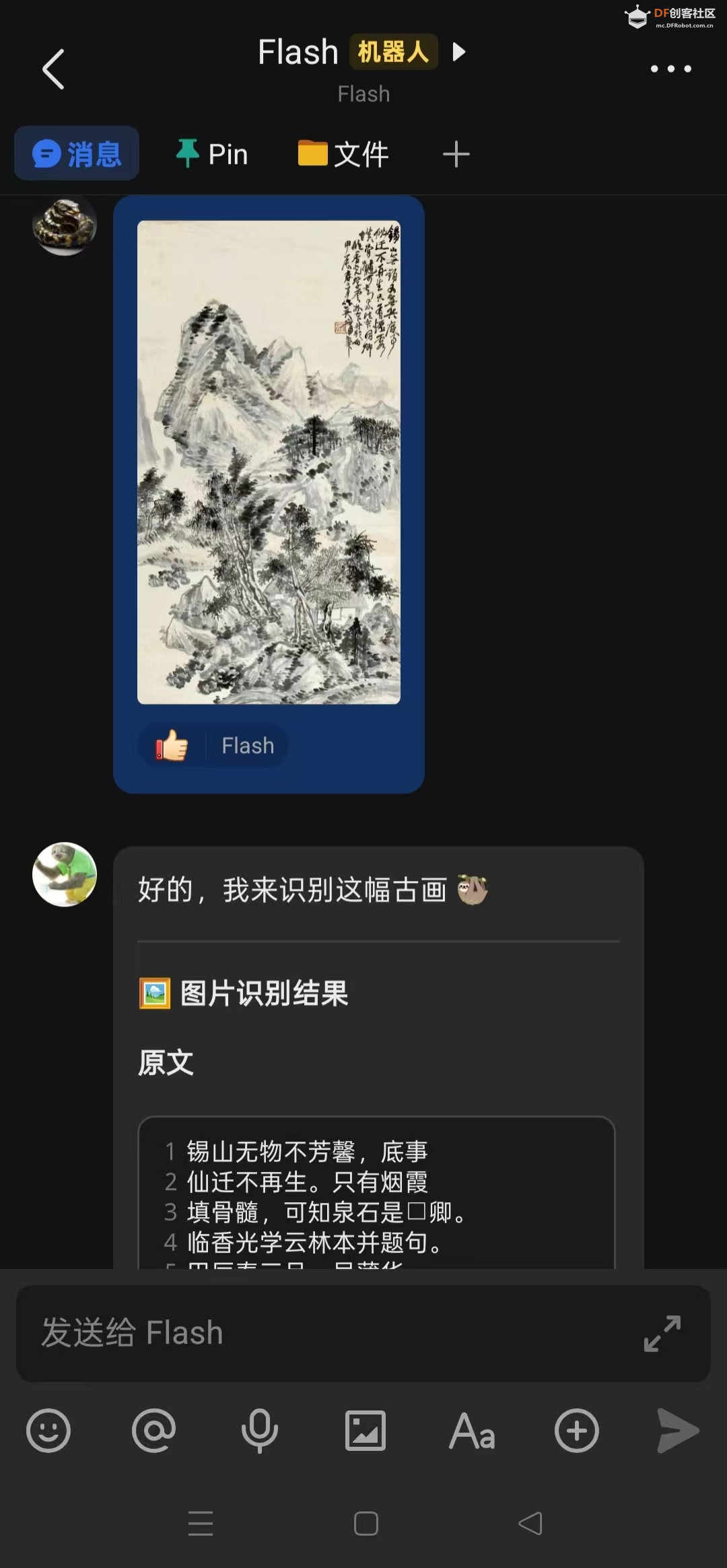
用户:[发送一张甲骨文图片]
助手:【识别文字】
逐字释读:
1. 王 - 象形字,表示王权
2. 祀 - 祭祀之意
...
【权威解读】
这是一片商代卜辞,内容关于...
(3) 配置要求阿里的这款kimi-k2.5可以完成识别要求,初期笔者调试时,visionTemperature设置为0.1,结果出来的结果全部方框,后来值调到0.3能够解析出文字。
{
"agents": {
"defaults": {
"visionModel": "dashscope_vision/kimi-k2.5",
"visionMaxTokens": 8192,
"visionTemperature": 0.3
}
},
"providers": {
"dashscope_vision": {
"apiKey": "sk-sp-xxxxxxxx",
"apiBase": "https://coding.dashscope.aliyuncs.com/v1"
}
}
}
(4) Nanobot 中看图识别甲骨文的核心实现。主要分为两部分:
- 1. 图像识别工具 (image_recognition.py)
-
- """Image recognition tool for ancient paintings and oracle bones.
- """
-
- import base64
- import httpx
- from nanobot.agent.tools.base import Tool
-
- # Use DashScope Kimi K2.5 for vision recognition
- DASHSCOPE_API_KEY = "sk-sp-*************"
- DASHSCOPE_API_BASE = "https://coding.dashscope.aliyuncs.com/v1"
- DASHSCOPE_VISION_MODEL = "kimi-k2.5"
-
-
- class ImageRecognitionTool(Tool):
- """Recognize text from ancient Chinese paintings or oracle bones."""
-
- name = "recognize_image"
- description = "Recognize text from images of ancient Chinese paintings or oracle bones."
-
- async def execute(self, image_path: str, **kwargs) -> str:
- """Recognize text from image."""
- # 读取并编码图片
- image_data = Path(image_path).read_bytes()
- b64_image = base64.b64encode(image_data).decode()
-
- # 关键 Prompt:识别甲骨文/古画
- prompt = """请识别这张图片中的所有文字内容。
-
- 如果是古画/书法:
- - 识别所有题跋、落款、印章文字
- - 直接输出文字,不要分析
-
- 如果是甲骨文:
- - 逐字识别甲骨文字
- - 给出每个字的释读
- - 直接输出,不要分析
-
- 只输出识别到的文字,不要添加任何分析或推测。看不清的字标注"□"。"""
-
- result = await self._call_api(headers, b64_image, mime_type, prompt)
- return f"【图片路径】{image_path}\n\n【识别文字】\n{result}"
-
- ---
- 2. 主循环处理逻辑 (loop.py:684-731)
-
- # 检测到图片时,使用 Kimi API 识别
- if msg.media:
- logger.info("Image detected, using Kimi K2.5 for recognition...")
- recognized_texts = []
-
- for image_path in msg.media:
- if image_path.endswith(('.jpg', '.jpeg', '.png')):
- from nanobot.agent.tools.image_recognition import ImageRecognitionTool
- recognizer = ImageRecognitionTool()
- result = await recognizer.execute(image_path=image_path)
- recognized_texts.append(result)
-
- if recognized_texts:
- recognized_content = "\n\n".join(recognized_texts)
- # 构建带自动搜索的 Prompt
- current_message = (
- f"{recognized_content}\n\n"
- "【任务】这是图片识别结果。请:\n"
- "1. 先展示识别的文字内容\n"
- "2. 根据识别内容提取关键词,搜索验证(甲骨文搜合集编号,古画搜作者作品)\n"
- "3. 对比官方内容,给出结论\n"
- "4. 格式:**原文** / **释读** / **主题** / **背景**\n\n"
- "最多搜索2次,给出完整答案。"
- )
-
- ---
- 流程总结
-
- 用户发图片 → Kimi K2.5 识别文字 → 提取关键词 → 搜索验证 → 输出结论
-
- 特点:
- - 使用 Kimi K2.5 视觉模型(识别能力强)
- - 支持甲骨文和古画/书法两种模式
- - 自动搜索验证(甲骨文搜合集编号)
- - 输出格式统一:原文/释读/主题/背景
三,给它看古画,展示出非常专业的效果
| 



 沪公网安备31011502402448
沪公网安备31011502402448
 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






