一、实践目标
本项目在行空板上外接USB摄像头,通过摄像头来识别人物名字。
二、知识目标
学习使用pytesseract库进行文字识别的方法。
三、实践准备
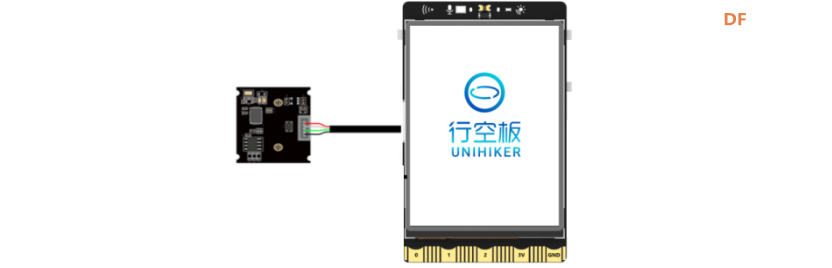
硬件清单:
软件使用:Mind+编程软件x1
四、实践过程
1、硬件搭建
1、将摄像头接入行空板的USB接口。
2、通过USB连接线将行空板连接到计算机。
2、软件编写
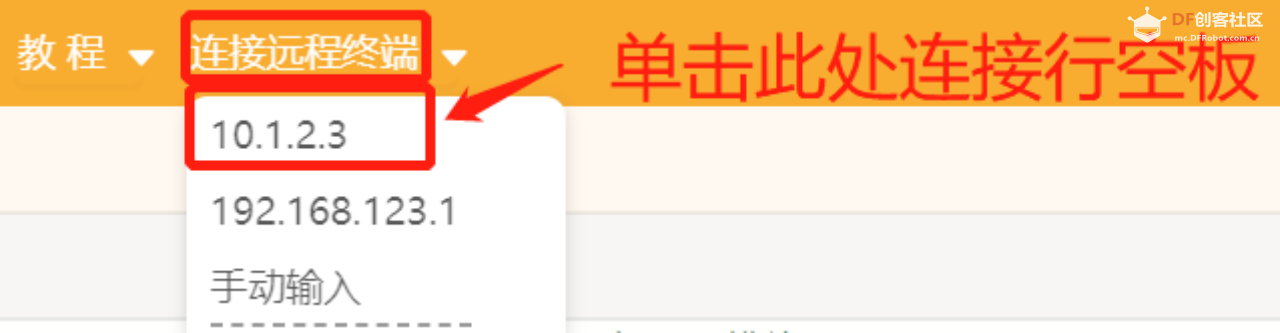
第一步:打开Mind+,远程连接行空板
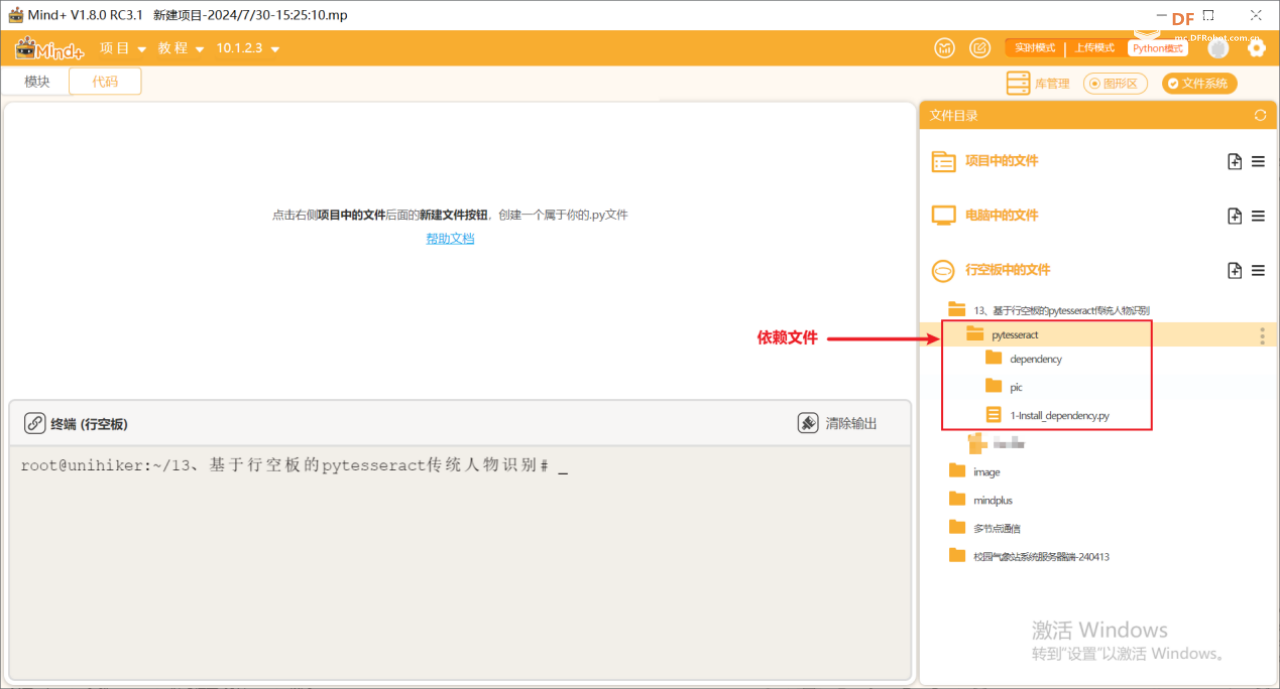
第二步:在“行空板的文件”中新建一个名为AI的文件夹,在其中再新建一个名为“基于行空板的pytesseract传统人物识别”的文件夹,导入本节课的依赖文件。
第三步:编写程序
在上述文件的同级目录下新建一个项目文件,并命名为“main.py”。
示例程序:
- # -*- coding: UTF-8 -*-
-
- # MindPlus
- # Python
- import sys
- sys.path.append("/root/mindplus/.lib/thirdExtension/nick-pytesseract-thirdex")
- # from pinpong.board import Board
- from pinpong.board import Board,Pin
- from pinpong.extension.unihiker import *
- # from pinpong.libs.dfrobot_speech_synthesis import DFRobot_SpeechSynthesis_I2C
- import time
- import cv2
- import pytesseract
- from PIL import Image,ImageFont,ImageDraw
- import os
- import numpy as np
-
-
- Board().begin()
- # p_gravitysynthesis = DFRobot_SpeechSynthesis_I2C()# 语音合成
- # p_gravitysynthesis.begin(p_gravitysynthesis.V2)
- def drawChinese(text,x,y,size,r, g, b, a,img):
- font = ImageFont.truetype("HYQiHei_50S.ttf", size)
- img_pil = Image.fromarray(img)
- draw = ImageDraw.Draw(img_pil)
- draw.text((x,y), text, font=font, fill=(b, g, r, a))
- frame = np.array(img_pil)
- return frame
-
- pytesseract.pytesseract.tesseract_cmd = r'/usr/bin/tesseract'
- cap = cv2.VideoCapture(0)
- cap.set(cv2.CAP_PROP_FRAME_WIDTH, 240)
- cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 320)
- cap.set(cv2.CAP_PROP_BUFFERSIZE, 1)
- cv2.namedWindow('cvwindow',cv2.WND_PROP_FULLSCREEN)
- cv2.setWindowProperty('cvwindow', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)
- while not cap.isOpened():
- continue
- print("start!")
- ShiBieNaRong = ''
- img_word1 = ''
- img_word2 = ''
-
- while True:
- cvimg_success, img_src = cap.read()
- cvimg_h, cvimg_w, cvimg_c = img_src.shape
- cvimg_w1 = cvimg_h*240//320
- cvimg_x1 = (cvimg_w-cvimg_w1)//2
- img_src = img_src[:, cvimg_x1:cvimg_x1+cvimg_w1]
- img_src = cv2.resize(img_src, (240, 320))
- cv2.imshow('cvwindow', img_src)
- key = cv2.waitKey(5)
- if key & 0xFF == ord('b'): # Press the "a" key on Unihiker will stop the program.
- print("退出视频")
- break
- # if (button_a.is_pressed()==True):
- elif key & 0xFF == ord('a'):
- ShiBieNaRong = []
- try:
- if not os.path.exists("/root/image/pic/"):
- print("The folder does not exist,created automatically")
- os.system("mkdir -p /root/image/pic/")
- except IOError:
- print("IOError,created automatically")
- break
- cv2.imwrite("/root/image/pic/image.png",img_src)
- time.sleep(0.2)
- img = Image.open('/root/image/pic/image.png')
- ShiBieNaRong = pytesseract.image_to_string(img, lang='chi_sim')[0:2]
- print(ShiBieNaRong)
-
-
- img_src = drawChinese(text=str(ShiBieNaRong),x=10, y=20,size=25,r= 50,g=200,b=0,a=0,img=img_src)
- cv2.imshow('cvwindow', img_src)
-
- cap.release() # Release usb camera. # 释放摄像头
- cv2.destroyAllWindows() # Destory all windows created by opencv. # 关闭所有窗口
3、运行调试
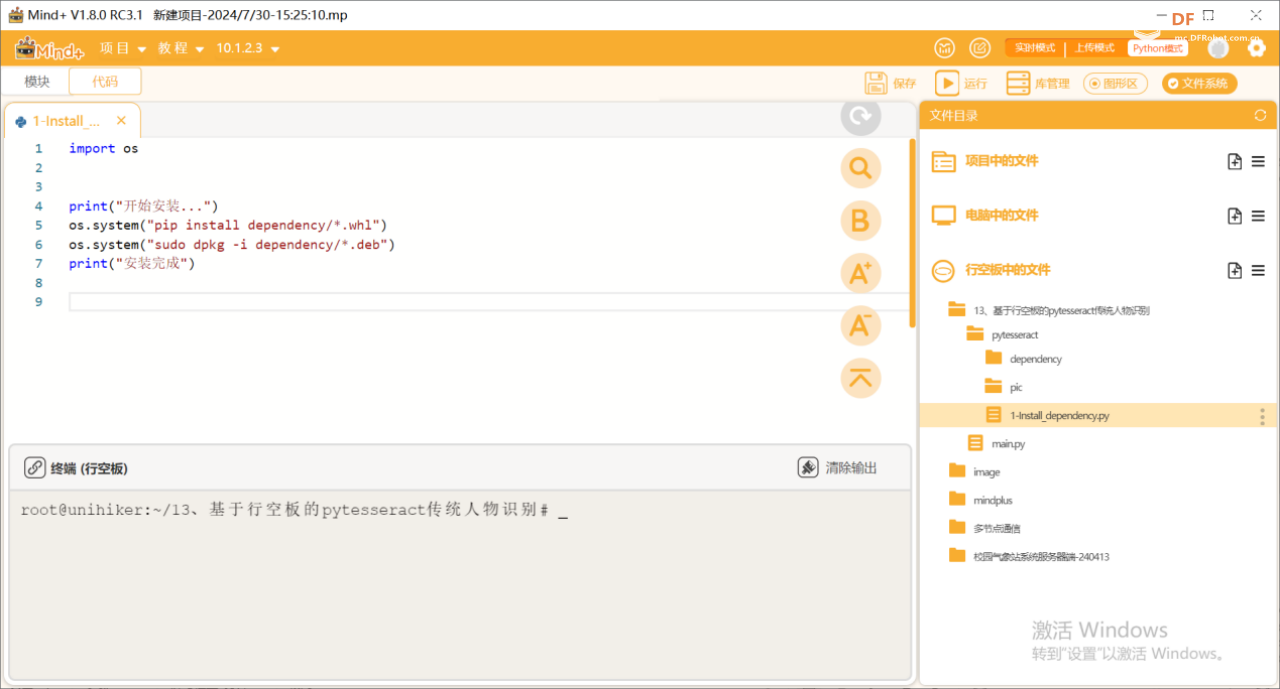
第一步:安装依赖库
运行pytesseract目录下1-Install_dependency.py程序文件,安装各个依赖库。
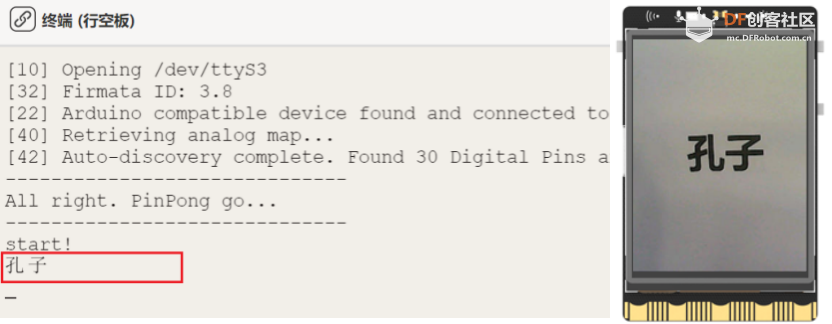
第二步:运行主程序
运行“main.py”程序,可以看到初始时屏幕上显示着摄像头拍摄到的实时画面,将摄像头画面对准任务名字,如这里为孔子,然后按下板载按键a,将此帧图像拍摄保存,之后自动识别图像上的文字,在Mind+软件终端,我们可以看到识别到的中文结果。
Tips:拍摄的图片保存在/root/image/pic这个路径下。
4、程序解析
这段程序通过使用OpenCV库调用摄像头,实时从摄像头读取图像,然后使用Tesseract进行OCR识别并将结果显示在图像上。具体流程如下:
①初始化:程序启动时,会导入所需的库,初始化UNIHIKER开发板,配置Tesseract命令路径,打开默认的摄像头设备,并设置摄像头的分辨率和缓冲区大小。接着,创建一个全屏窗口用于显示图像。
②定义函数:定义一个用于在图像上绘制中文字符的函数drawChinese。
③主循环:程序进入一个无限循环,在每次循环中,程序会执行以下操作:
· 从摄像头读取一帧。如果读取失败,则继续下一次循环。
· 检查按键事件:
· 如果按下'b'键,程序退出循环。
· 如果按下'a'键,程序捕获当前图像并保存到指定路径,然后使用Tesseract识别图像中的中文字符,并将结果打印到终端。
· 在图像上绘制识别到的中文字符,并在窗口中显示处理后的图像。
④结束:当主循环结束时,程序会释放摄像头设备,并关闭所有OpenCV窗口。
五、知识园地
1. 了解pytesseract库
pytesseract 是 Tesseract OCR 引擎的 Python 封装库,用于从图像中提取文本。它提供了简便的接口,使得在 Python 程序中能够轻松实现光学字符识别(OCR)。
功能
1. 图像文字识别:从各种图像格式(如 PNG、JPEG、BMP 等)中提取文本。
2. 多语言支持:能够识别多种语言的文本。
3. 布局分析:处理复杂文档布局,包括多列文本和表格。
4. 位置信息提取:提供识别到的字符或单词在图像中的位置坐标。
5. 多种输出格式:支持纯文本、字典格式、HOCR(HTML OCR)格式等。
特点
1. 开源免费:基于开源的 Tesseract OCR 引擎,免费使用。
2. 跨平台:支持 Windows、macOS 和 Linux 系统。
3. 高准确性:Tesseract 引擎经过多年的开发和优化,具有较高的识别准确性。
4. 易于集成:提供简单的 Python 接口,便于与其他 Python 项目和库集成。
| 



 编辑选择奖
编辑选择奖



 沪公网安备31011502402448
沪公网安备31011502402448

 置顶卡
置顶卡 变色卡
变色卡 千斤顶
千斤顶






